






































Know All About Q Learning
by Arnab Dey Technology Published on: 08 February 2022 Last Updated on: 17 May 2025
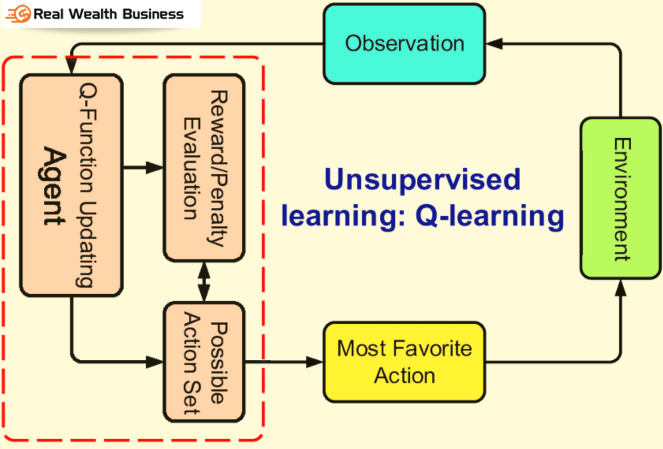
The implementation and use of the Internet of Things (IoT technology) always require the development of new skills to solve multi-step problems. The unique Q Learning system is one of the advanced RL algorithms that implies reinforcement learning.
The strategy has already been implemented in many IT companies and is yielding results. At the same time, reinforcement learning has its own characteristics, advantages, and disadvantages.
Main features and characteristics of Q learning
The described strategy is completely subject to mathematical dependencies and has the following characteristics:
- A large number of states are determined by the complexity of the task (S).
- The number of planned actions corresponds to a lot of defined states (A).
- When pairs of state and action match, a certain reward (R) is assigned.
- The use of non-linear dependencies in determining the variations of the transition to a neighboring state (when the state and action coincide – P).
- Determination of the index of reduction of the reward index, depending on its importance and the need to receive it.
In this way, the strategy is completely controlled by the data set and the number of state transitions, which provides a structured data classification.
The principle of operation of the system
The control strategy and operating principle of the system are subject to the following simple algorithm, consisting of 3 steps:
- The program ensures that the action is performed in its current state.
- The software environment recognizes combinations of action and state, which serves as a signal to send a reward in response.
- The program begins to consider the next stage, which ensures the repetition of the cyclic interaction of the agent, state, and movement.
Cycling continues until the user artificially terminates the process, or the program reaches a pre-set boundary condition.
What is Q-learning?

Q-learning is a cyclical process in which the system automatically updates the transition to the next stage until it reaches the Q* value.
The most primitive Q-learning scheme is an ordered matrix, in which a value Q is set opposite each pair of states-actions.
There are some intermediate results between the current indicators that are not expressed in digital format. In such cases, when the average value of the pair is reached in an approximate iteration, the knowledge of Q is determined by interpolation.
The system gradually remembers each iteration, which contributes to the gradual accumulation of knowledge in memory. In the case of the occurrence and calculation of the approximate average result, this indicator is automatically entered into the matrix, which expands and updated.
The described strategy is effective, subject to the analysis of a small amount of data. In the case of performing a large number of overhead tasks, the algorithm implies repeated access to the dependence of the action and the state.
This leads to millions of calculations of intermediate values Q by the interpolation method, which requires a lot of time. In short, for volumetric algorithms, such a system is extremely inefficient.
Ways to solve the problem
The problem described above due to the impossibility of analyzing a large amount of data due to multiple iterations leads many developers to think.
The best way out of this problem is the use of artificial intelligence technology, based on the transmission of vector data, a set of characters, or graphic fragments through a dense membrane of neural networks.
The neural network operates in accordance with a fundamentally different algorithm – the matrix itself offers the agent various iteration options, which do not require time spent on calculating the average values during interpolation.
The agent only identifies all the data transmitted to it, after which it chooses the result that is closest to the reliable value.
The Q coefficient matrix, according to the current value of the state and action pair, is updated automatically, which significantly reduces the time, since it does not require the calculation of dependencies by trial fitting.
Practical application of Q-learning

This strategy helps in the automatic configuration of WEB applications. As a rule, modern applications of the Internet of Things have a mono-level structure, which significantly complicates the classification of data and requires the use of neural networks.
When using Internet steam-awakening, Q-learning plays an important but simple role – when analyzing the current matrix and separating the action-state pair, the system offers a reward in the form of a set of commands to refer to the previous, next, or save the current state.
The reward index depends on the time it takes the system to form a response to a request.
Another important environment in which the strategy under consideration can be used is news and recommendations for the user.
A large number of iterations and the use of digital neural networks provide a high coefficient of response variability, which allows the user to communicate with the robot as with a living person.
The mechanism defines queries, identifies, and classifies their significance, resulting in the formation of model vertices and vectors.
The finished digital template is filtered through a neural network, after which the machine automatically generates a reward and sends a response to the user.
The last function for which Q-learning is used is traffic control. The system creates the desired combination of state and action pairs, tracks transitions, which helps to determine network congestion.
When accessing the system, the reward is expressed in the form of a signal notifying about the possibility of continuing the work, or about the need to clean up data from the cluster, since the main functions are slowing down.
The main advantage of the considered theory is the ease of operation of the system without human participation in the conditions of approximate iterations, that is, uncertainty.
In such situations, the reaction of the algorithm is close to expressing the thoughts or emotions of a person, which is one of the stages in the progress of artificial intelligence technologies.
Reinforcement learning is now being actively introduced into the business management system for many large companies around the world.
These artificial intelligence technologies provide improved customer service, allow you to control the staff and management, as well as significantly reduce costs and optimize the profit of the enterprise.
Read Also:







Related



Technology
